

Perkembangan teknologi digital dalam beberapa tahun terakhir telah mendorong penggunaan machine learning di berbagai bidang, mulai dari bisnis, kesehatan, hingga pendidikan. Teknologi ini memungkinkan komputer mempelajari pola dari data dan menghasilkan prediksi atau keputusan secara otomatis. Banyak orang beranggapan bahwa keberhasilan sebuah model machine learning sangat bergantung pada algoritma yang digunakan. Namun, dalam praktiknya terdapat faktor lain yang tidak kalah penting, yaitu kualitas dataset yang digunakan dalam proses pembelajaran model.
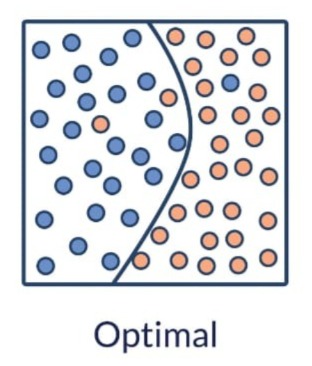 Dataset merupakan kumpulan data yang digunakan untuk melatih dan mengevaluasi model machine learning. Melalui dataset tersebut, model mempelajari hubungan antarvariabel serta pola yang terdapat dalam suatu fenomena. Dengan kata lain, data menjadi fondasi utama dalam proses pembelajaran model. Oleh karena itu, pemilihan dataset yang tepat menjadi langkah awal yang sangat penting dalam pengembangan model berbasis data. Model yang kompleks sekalipun tidak akan memberikan hasil yang optimal jika dilatih menggunakan data yang kurang relevan atau berkualitas rendah.
Dataset merupakan kumpulan data yang digunakan untuk melatih dan mengevaluasi model machine learning. Melalui dataset tersebut, model mempelajari hubungan antarvariabel serta pola yang terdapat dalam suatu fenomena. Dengan kata lain, data menjadi fondasi utama dalam proses pembelajaran model. Oleh karena itu, pemilihan dataset yang tepat menjadi langkah awal yang sangat penting dalam pengembangan model berbasis data. Model yang kompleks sekalipun tidak akan memberikan hasil yang optimal jika dilatih menggunakan data yang kurang relevan atau berkualitas rendah.
Langkah pertama dalam memilih dataset adalah memastikan kesesuaian data dengan tujuan analisis. Dataset yang digunakan harus relevan dengan permasalahan yang ingin diselesaikan. Misalnya, jika tujuan model adalah memprediksi harga rumah, maka dataset yang digunakan sebaiknya memuat variabel yang berkaitan dengan harga properti seperti luas bangunan, lokasi, jumlah kamar, serta fasilitas yang tersedia. Data yang tidak berkaitan dengan permasalahan yang dianalisis akan menyulitkan model dalam menemukan pola yang bermakna.
Setelah memastikan relevansi data, perhatian berikutnya perlu diarahkan pada kualitas dataset itu sendiri. Dalam praktiknya, data yang diperoleh sering kali mengandung berbagai permasalahan seperti nilai yang hilang (missing values), data duplikat, atau kesalahan pencatatan. Jika masalah tersebut tidak ditangani dengan baik, model yang dihasilkan dapat memberikan prediksi yang kurang akurat. Oleh karena itu, sebelum digunakan dalam proses pelatihan model, dataset biasanya perlu melalui tahap pembersihan data (data cleaning) untuk meningkatkan kualitas dan konsistensi informasi di dalamnya.
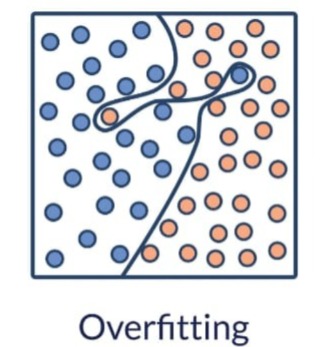 Selanjutnya, penting juga untuk mempertimbangkan jumlah dan keberagaman data. Dataset yang terlalu kecil biasanya tidak mampu merepresentasikan kondisi sebearnya dari populasi. Akibatnya, model dapat mengalami overfitting, yaitu kondisi ketika model terlalu menyesuaikan diri dengan data pelatihan tetapi kurang mampu melakukan prediksi pada data baru. Dataset yang lebih besar dan beragam umumnya membantu model mempelajari pola yang lebih umum sehingga menghasilkan prediksi yang lebih stabil.
Selanjutnya, penting juga untuk mempertimbangkan jumlah dan keberagaman data. Dataset yang terlalu kecil biasanya tidak mampu merepresentasikan kondisi sebearnya dari populasi. Akibatnya, model dapat mengalami overfitting, yaitu kondisi ketika model terlalu menyesuaikan diri dengan data pelatihan tetapi kurang mampu melakukan prediksi pada data baru. Dataset yang lebih besar dan beragam umumnya membantu model mempelajari pola yang lebih umum sehingga menghasilkan prediksi yang lebih stabil.
Dalam beberapa kasus, permasalahan lain yang muncul adalah ketidakseimbangan distribusi data. Dataset tertentu memiliki distribusi kelas yang tidak seimbang, di mana jumlah data pada satu kategori jauh lebih besar dibandingkan kategori lainnya. Sebagai contoh, pada dataset deteksi penipuan transaksi, jumlah transaksi normal biasanya jauh lebih banyak dibandingkan transaksi penipuan. Kondisi ini dapat membuat model cenderung memprediksi kelas mayoritas dan mengabaikan kelas minoritas yang sebenarnya penting untuk dianalisis.
Di samping karakteristik data, sumber dataset juga menjadi aspek yang perlu diperhatikan. Dataset yang berasal dari sumber terpercaya umumnya memiliki kualitas yang lebih baik dan dapat dipertanggungjawabkan. Saat ini banyak platform yang menyediakan dataset terbuka untuk keperluan penelitian dan pengembangan machine learning, seperti Kaggle dan UCI Machine Learning Repository. Meskipun demikian, pengguna tetap perlu melakukan evaluasi terhadap dataset tersebut untuk memastikan kesesuaiannya dengan kebutuhan analisis.
Tidak kalah penting, penggunaan dataset juga harus mempertimbangkan aspek etika dan privasi data. Beberapa dataset dapat mengandung informasi sensitif yang berkaitan dengan individu atau kelompok tertentu. Oleh karena itu, pemanfaatan data harus dilakukan secara bertanggung jawab dengan memperhatikan prinsip perlindungan data, sehingga penggunaan teknologi tidak menimbulkan dampak negatif bagi pihak tertentu.
Dengan demikian, keberhasilan machine learning tidak hanya ditentukan oleh algoritma yang digunakan, tetapi juga oleh kualitas data yang menjadi dasar pembelajaran model. Dataset yang relevan, bersih, cukup besar, dan berasal dari sumber terpercaya akan membantu menghasilkan model yang lebih akurat dan dapat diandalkan. Dengan memahami pentingnya pemilihan dataset sejak awal, pengembang dan peneliti dapat memaksimalkan potensi machine learning dalam menyelesaikan berbagai permasalahan di dunia nyata.
Referensi :
James, G., Witten, D., Hastie, T., & Tibshirani, R. (2021). An Introduction to Statistical Learning. Springer.
Géron, A. (2022). Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow. O’Reilly Media.
UCI Machine Learning Repository. https://archive.ics.uci.edu
Kaggle Datasets. https://www.kaggle.com/datasets
